
Pour cette nouvelle année 2012, je vais commencer gros avec un article qui traine depuis des mois maintenant. En fait, ce sera un gros clin d’œil à la (seule) période réellement passionnante de cette seconde année de Master Ingénierie Informatique : la mise en œuvre d'une architecture HA (High Availability).
De plus, ayant échoué (de peu) à ce projet durant ma formation malgré l'investissement personnel, j'ai souhaité le refaire par moi-même car cela m'a passionné et plus tard, j'espère que j'aurais l'occasion de faire plus que configurer des vhosts !
Accès rapide
Au vu de la taille du sous-menu, cet article m'a pris un certain temps pour le rédiger et faire en sorte qu'il soit propre et cohérent. Si malgré cela, certains points sont pas clairs ou carrément faux, votre contribution me fera grand honneur. Merci d'avance.
- Qu'est-ce qu'un cluster ?
- Environnement du projet
- Création et configuration des VM
- Installation de Debian
- Installation des logiciels
- Configuration réseau
- Configuration des LVMs
- Configuration des logiciels
- DRBD
- Apache
- MySQL
- Corosync
- Clonage de la VM
- Mettre à jour le hostname
- Mettre à jour les interfaces réseau
- Mettre à jour l'adresse IP statique
- Synchronisation DRBD
- Pacemaker
- Les ressources Pacemaker
- Ajouter la ressource d'IP virtuelle
- Ajouter la ressource Apache
- Ajouter la ressource MySQL
- Ajouter la ressource DRBD et celle du système de fichier
- Contraintes et ordre des ressources
- Dumper et injecter sa configuration
- Tests
Qu'est-ce qu'un cluster ?
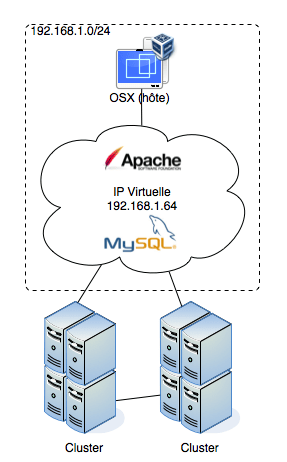
D'après Wikipédia et ce que j'ai appris avec mes cours, une architecture en cluster (ou en grappe) est un regroupement de machines identiques (OS et services). Ces machines sont appelées des « nœud » et de nos jours, avec la virtualisation, ces nœuds sont créés à la volée pour différents usages.
Il ne faut pas confondre avec l'architecture en grille (grid system) qui ne respecte pas les même propriétés. Une architecture en cluster est homogène, fortement couplée et géographiquement située sur un même site alors qu'une architecture en grille est distribuée, faiblement couplée et sa configuration (hardware et software) est hétérogène.
Un grid system est plus adapté pour fournir différents services (serveur d'application, de jeux, Web, de fichier, etc.) alors qu'un cluster sera plus adapté pour justement faire de la haute disponibilité et de la répartition de charge ; sans oublier la notion de puissance de calcule.
Ci-contre un schéma global du projet que nous allons réaliser dans cet article. Nous n'aurons pas 8 nœuds mais juste 2 (ici, c'est pour illustrer ce qu'est une ferme de clusters).
Environnement du projet
Voici donc les éléments clés de notre projet :
- Debian 6 (« Squeeze ») virtualisé avec VirtualBox
- Corosync 1.2.1
- Pacemaker 1.0.9
- DRBD 8.3.7
Pour avoir réalisé mon projet à la fac sur Fedora 14, je souhaite ici changer d'architecture système (histoire de me faire les dents sur plusieurs systèmes).
Voici donc un schéma un peu plus détaillé de notre projet :
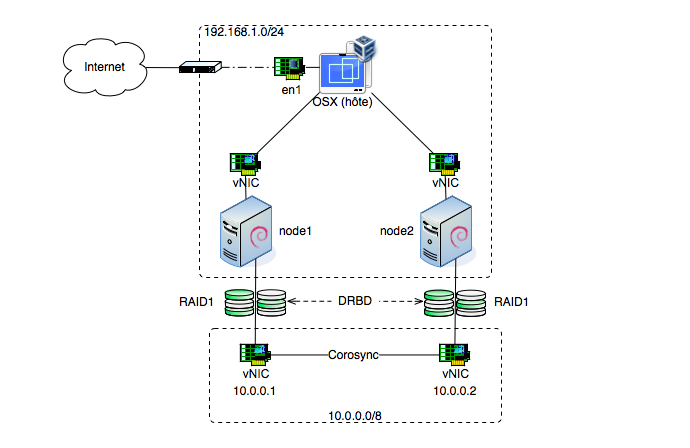
Nous aurons deux machines (nœuds) qui seront donc des purs clones (même au niveau disque) sur lesquels nous auront 3 disques durs dont 2 qui serviront à monter un périphérique RAID1. Dessus, un volume logique sur lequel on montera un système de fichier ReiserFS qui accueillera les données de notre pile LAMP.
Tous les services sont configurés de la même manière sur les 2 nœuds et seront gérés par Pacemaker (coordonné par Corosync) et bien évidemment, les données seront synchronisées à l'aide de DRBD.
Ca vous branche ? On attaque la bête ?
Création et configuration des VM
Inutile de vous dire de télécharger VirtualBox hein ?
Créons notre premier nœud :
pwd
~/VirtualBox VMs
curl https://cdimage.debian.org/debian-cd/6.0.3/i386/iso-cd/debian-6.0.3-i386-netinst.iso -o debian-6.0.3-i386-netinst.iso
VBoxManage createvm --name N1 --ostype Debian --register
cd N1
VBoxManage modifyvm N1 --memory 384 --vram 12 --pae off --rtcuseutc on --boot1 dvd --boot2 disk --boot3 none --boot4 none
VBoxManage modifyvm N1 --nictype1 82540EM --cableconnected1 on --macaddress1 auto --nic1 bridged --bridgeadapter1 en1 --nicpromisc1 allow-all
VBoxManage modifyvm N1 --nictype2 82540EM --cableconnected2 off --macaddress2 auto --nic2 intnet
VBoxManage storagectl N1 --name "IDE Controller" --add ide --hostiocache on --bootable on
VBoxManage storagectl N1 --name "SATA Controller" --add sata --sataportcount 3 --bootable on
VBoxManage createhd --filename N1.vdi --size 2048
VBoxManage createhd --filename N1-disk1.vdi --size 1024
VBoxManage createhd --filename N1-disk2.vdi --size 1024
VBoxManage storageattach N1 --storagectl "IDE Controller" --port 0 --device 0 --type dvddrive --medium ../debian-6.0.3-i386-netinst.iso
VBoxManage storageattach N1 --storagectl "SATA Controller" --port 0 --device 0 --type hdd --medium N1.vdi
VBoxManage storageattach N1 --storagectl "SATA Controller" --port 1 --device 0 --type hdd --medium N1-disk1.vdi
VBoxManage storageattach N1 --storagectl "SATA Controller" --port 2 --device 0 --type hdd --medium N1-disk2.vdi
VBoxManage startvm N1
Installation de Debian
Une fois que votre VM a bien démarré, configurez bien votre clavier, utilisateur, etc. Et lorsque vous arrivez à l'utilitaire de partition, soyez attentif :
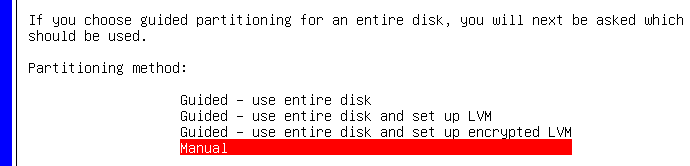
Créez une table de partition sur chacun des périphériques puis sélectionnez le gestionnaire RAID :
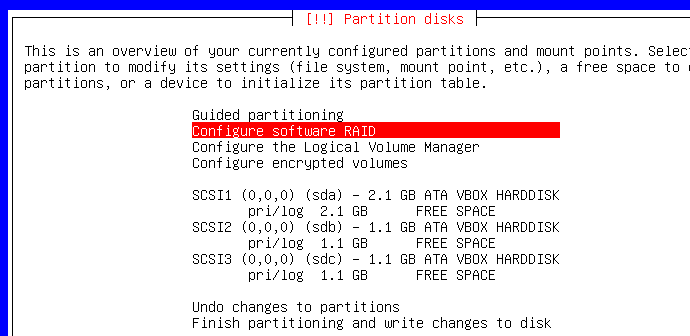
On veut donc créer un périphérique RAID :
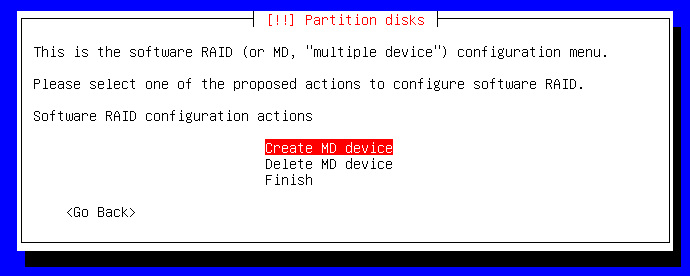
Au vu du nombre de disques, on fera du RAID1 (mirorring). Si vous voulez faire du RAID5, RAID10 ou même RAID15, il vous faudra plus de disques...
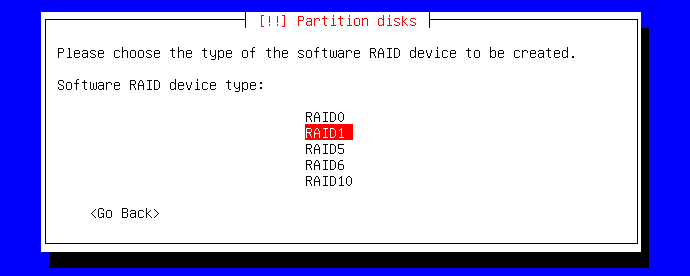
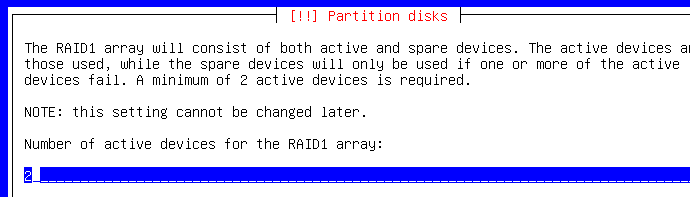
Donc ici, le gestionnaire demande bien au minimum 2 disques (il faut qu'ils aient la même taille) pour le RAID1 :
Aucun périphérique de parité ici :
Sélectionnez vos périphériques mais PAS /dev/sda car ce sera le périphérique sur lequel sera monté l'OS :
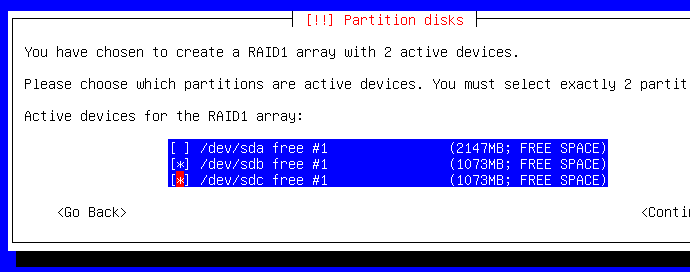
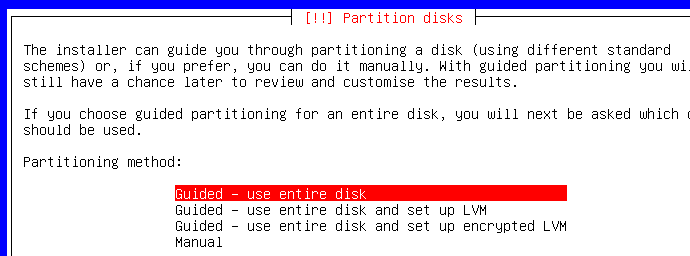
Parfait ! Si vous n'avez pas la même image que celle qui suit, c'est qu'il y a un soucis. Choisissez le partionneur guidé pour /dev/sda maintenant :
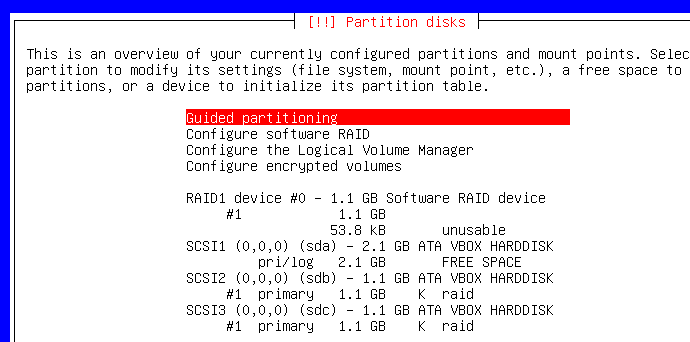
Là, c'est comme vous voulez...
Par contre, ne soyez pas stupide en sélectionnant /dev/sdb ou /dev/sdc puisque nous venons de créer un périphérique RAID1 avec. Sélectionnez /dev/sda :
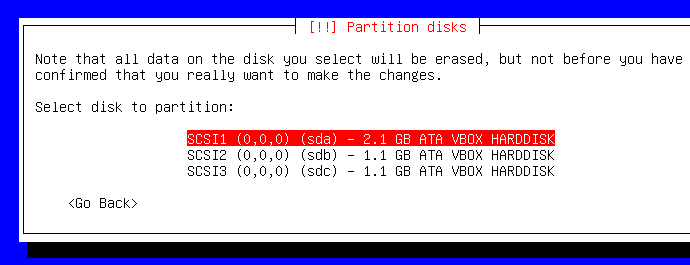
Je ne suis pas un grand expert de Linux donc je choisis la facilité là :

Debian prend par défaut EXT3, pourquoi ? Je ne sais pas. Perso', je préfère passer en EXT4 (bien que cela n'aura pas d'importance pour ce projet) :
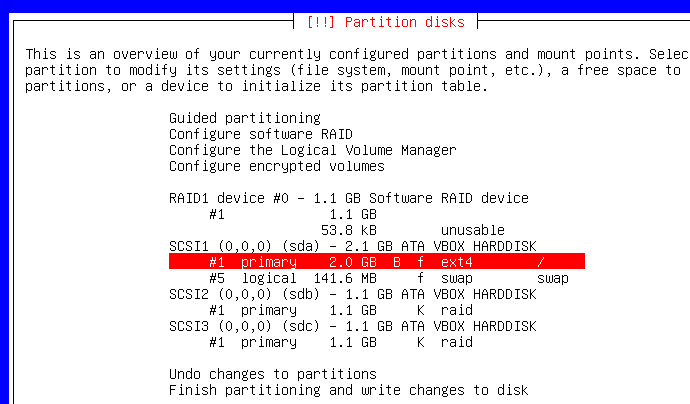
Quand vous avez fini, altérez les tables de partitions et continuez l'installation.
Installation des logiciels
Quand vous devrez sélectionner les services à installer, sélectionnez bien évidemment « Web server » et « SSH server » mais je vous déconseille d'installer la base de données SQL qui semble générer des erreurs ici : on s'en occupera plus tard.
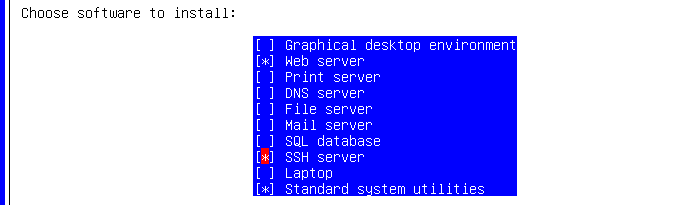
Finissez l'installation, redémarrez et connectez-vous en root (comme pour tout le reste du projet) pour lancer les installations complémentaires :
aptitude -y install vim ntp lvm2 reiserfsprogs php5 mysql-server corosync pacemaker drbd8-utils
sed -i.bak "s/TIMEOUT=5/TIMEOUT=1/g" /etc/default/grub
sed -ri 's/GRUB_CMDLINE_LINUX_DEFAULT="(.*)"/GRUB_CMDLINE_LINUX_DEFAULT="\1 vga=789"/g' /etc/default/grub
update-grub
sed -i.bak 's/XKBMODEL=".*"/XKBMODEL="macbook78"/g' /etc/default/keyboard
sed -i 's/XKBLAYOUT=".*"/XKBLAYOUT="fr"/g' /etc/default/keyboard
sed -i.bak 's/FONTFACE=".*"/FONTFACE="VGA"/g' /etc/default/console-setup
halt -t now
Nous venons ici d'installer quelques outils et ensuite, j'ai changé la configuration de GRUB pour réduire le temps d'attente, changer la résolution (800x600) puis j'ai fini par reconfigurer la disposition de mon clavier (ma machine hôte est un MacBook Pro) ainsi que la font de la console (qui est trop légère par défaut).
Configuration réseau
Lors de la création de notre VM, je ne sais pas si vous avez fait attention mais la seconde carte réseau n'était pas connectée ( « --cableconnected2 off »). N'oubliez pas de la rebrancher avant de continuer :
VBoxManage modifyvm N1 --cableconnected2 on
VBoxManage startvm N1
Sur notre VM, nous avons donc 2 interfaces réseaux, une qui va communiquer avec l'extérieur et une qui communiquera qu'avec l'autre VM pour DRBD (pontage réseau). Normalement, l'interface réseau par défaut (celle par laquelle l'installation a été faite) se connecte automatiquement via DHCP donc on ne vas pas s'en soucier.
Cependant, nous avons besoin de configurer l'autre interface eth1 (théoriquement) de manière à avoir un adressage statique :
cat << EOT >> /etc/network/interfaces
auto eth1
iface eth1 inet static
address 10.0.0.1
network 10.0.0.0
netmask 255.0.0.0
broadcast 10.255.255.255
gateway 10.255.255.254
EOT
cat << EOT >> /etc/hosts
10.0.0.1 node1
10.0.0.2 node2
EOT
On n'oublie pas de relancer le service réseau et de ré-attribuer une IP dynamique avec le DHCP :
service networking restart
dhclient eth0
Configuration des LVMs
DRBD peut se greffer directement sur un périphérique RAID mais nous n'allons pas le faire car si nous souhaitons redimensionner la taille du volume, nous pourrons pas le faire sans devoir tout re-configurer. Pour cela, nous allons créer un groupe de volumes logiques qui lui pourra être modifié à chaud. Pour cela, il va falloir créer une table de partition LVM sur notre périphérique RAID « md0 » :
fdisk /dev/md0
> n # Nouvelle partition
> p # Primaire
> 1 # Partition n°1
> ENTER # Premier bloc par défaut
> ENTER # Dernier bloc par défaut
> t # Type de partition
> 8e # Type LinuxLVM
> p # Affichage de la partition pour vérification
> w # Altération du périphérique
Ok, nous venons de créer /dev/md0p1 qui sera notre partition LVM pour DRBD. Créons un groupe de volume et son volume virtuel dessus :
pvcreate /dev/md0p1
vgcreate cluster /dev/md0p1
lvcreate -n webcluster -l 100%FREE cluster
lvs # Affichage de la LVM créée
Cette fois-ci, tout est prêt pour accueillir un système de fichier... Mais avant cela, nous allons mettre en place la réplication bas-niveau avec DRBD. Même si orpheline, on configure le maximum maintenant pour n'avoir qu'à cloner la VM par la suite.
Configuration des logiciels
Dans cette partie de l'article, nous allons configurer tous les logiciels qui peuvent l'être sans avoir besoin de l'autre nœud.
DRBD
Bon, je ne vais pas vous expliquer en détails ma configuration de ma ressource DRBD car je l'ai déjà commenté puis le site de DRBD est plutôt complet.
Voici donc le fichier de configuration que nous allons utiliser :
# r0.res
global {
# Enables statistics usage
usage-count yes;
}
common {
# Maner to sync data, it's flagged as completed when both disks has written
protocol C;
}
resource r0 {
# Stores data meta-data in the volume
meta-disk internal;
# DRDB device
device /dev/drbd1 minor 1;
# Volume
disk /dev/mapper/cluster-webcluster;
syncer {
# Hash method to check data integrity
verify-alg sha1;
# Network sync speed
rate 100M;
}
net {
# TODO: explain why
allow-two-primaries;
# Split-brain policies
after-sb-0pri discard-younger-primary;
after-sb-1pri discard-secondary;
after-sb-2pri call-pri-lost-after-sb;
}
# node1
on node1 {
address 10.0.0.1:7789;
}
# node2
on node2 {
address 10.0.0.2:7789;
}
}
Note : la documentation de DRDB est très complète donc allez y faire un tour !
Ce fichier r0.res est donc à copier dans /etc/drbd.d mais surtout n'oubliez pas commenter cette ligne dans /etc/drbd.conf :
include "drbd.d/global_common.conf";
Note : mon fichier r0.res contient déjà la configuration globale que je veux.
Nous allons ensuite initialiser la ressource et monter notre système de fichier dessus afin de continuer à configurer les autres services :
drbdadm create-md r0
modprobe drbd
drbdadm down r0
drbdadm up r0
drbdadm -- --overwrite-data-of-peer primary r0
Avec ces 5 commandes, on vient de :
- Créer les méta-données du volume (initialiser le volume)
- Déclarer DRDB comme module additionnel du noyau Linux
- Désactiver (déconnecter et détacher) le périphérique DRDB
- Activer (attacher et connecter) le périphérique DRDB
- Décréter notre machine comme maître
Note : vous pouvez voir l'état actuel de DRDB avec la commande suivante :
cat /proc/drbd
version: 8.3.7 (api:88/proto:86-91)
srcversion: EE47D8BF18AC166BE219757
1: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r----
ns:0 nr:0 dw:0 dr:200 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:1044412
Note : le détail des statuts sur le site de DRDB.
Nous allons maintenant pouvoir monter dessus notre système de fichier :
mkfs.reiserfs /dev/drbd1
mkdir /var/cluster
mount /dev/drbd1 /var/cluster
Note 1 : pour que le volume /dev/drbd1 puisse être monté, il faut qu'il soit déclaré en « primary» auprès de DRDB !
Note 2 : j'ai choisi ici le système de fichier ReiserFS car il est très performant sur la gestion de fichiers de petite taille (temps d'accès) et permet d'être redimensionner à la volée. Donc vraiment idéal pour contenir des fichiers destinés au Web.
Apache
Si vous arrivez à ces lignes et que vous n'avez jamais configuré un serveur Apache... Et bien, je crois que je serais déçu :ermm:. Sinon, on continue : configurez votre serveur Apache afin qu'il pointe dans /var/cluster/www au lieu de /var/www mais surtout, super important : activez le mod_status si inactif !
mkdir /var/cluster/www
cd /etc/apache2
cat << EOF > sites-available/app
<VirtualHost *:80>
ServerAdmin webmaster@localhost
DocumentRoot /var/cluster/www
<Directory /var/cluster/www/>
Options -Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
EOF
rm sites-enable/*
ln -s sites-available/app sites-enable/000-app
Chose importante aussi : n'oubliez pas de changer le format de vos logs dans /etc/apache2/apache2.conf car l'accès ici ne sera pas direct puisqu'il sera géré par Pacemaker donc il faut remplacer les « %h » par « %{X-Forwarded-For}i » :
LogFormat "%v:%p %{X-Forwarded-For}i %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" vhost_combined
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %O" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
Une fois que c'est pret, relancez votre serveur Apache, créez un fichier index bidon et testez depuis votre machine hôte :
service apache2 restart
echo "" > /var/cluster/www/index.php
Voici donc le résultat :
curl -i https://192.168.1.8
HTTP/1.1 200 OK
Date: Sun, 22 Jan 2012 13:07:10 GMT
Server: Apache/2.2.16 (Debian)
X-Powered-By: PHP/5.3.3-7+squeeze3
Vary: Accept-Encoding
Content-Length: 5
Content-Type: text/html
node1
MySQL
Maintenant que notre serveur Web fonctionne, nous allons nous occuper de notre serveur de base données. Pour cela, on va devoir changer le répertoire par défaut où se trouvent les données et changer l'adresse d'accès de notre serveur :
service mysql stop
Dans le fichier /etc/mysql/my.cnf, changez et/ou ajouter les paramètres suivants dans la section « [mysqld] » :
[mysqld]
datadir = /var/cluster/mysql
symbolic-links = 0
Ensuite, on va déplacer le répertoire des données au bon endroit :
mv /var/lib/mysql /var/cluster
Relançons notre serveur MySQL et faisons quelques opérations dessus :
service mysql start
mysql -p
On va en profiter pour créer un utilisateur, une base de données et lui permettre de se connecter à partir de notre machine hôte :
CREATE USER 'eexit'@'192.168.1.%' IDENTIFIED BY 'eexit';
CREATE DATABASE cluster;
GRANT SELECT, INSERT ON cluster.* TO 'eexit'@'192.168.1.%';
FLUSH PRIVILEGES;
Note : si vous voulez tester depuis votre hôte, vous devez paramétrer « bind-address » (toujours dans /etc/mysql/my.cnf) avec l'adresse DHCP de votre VM pour pouvoir vous connecter depuis votre hôte :
mysql -h 192.168.1.x -u eexit -p eexit
On va remplir un peu la base données si vous voulez bien...
-- products.sql
CONNECT cluster;
CREATE TABLE product (
id SMALLINT NOT NULL AUTO_INCREMENT,
name VARCHAR(30) NOT NULL,
price SMALLINT NOT NULL,
quantity SMALLINT NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO product(name, price, quantity) VALUES('A Games of Thrones', 11, 9);
INSERT INTO product(name, price, quantity) VALUES('A Clash of Kings', 11, 2);
INSERT INTO product(name, price, quantity) VALUES('A Storm of Swords', 11, 12);
INSERT INTO product(name, price, quantity) VALUES('A Feast for Crows', 11, 19);
INSERT INTO product(name, price, quantity) VALUES('A Dance with a Dragon', 11, 3);
mysql -f -p < products.sql
Enfin, quand vous avez fini, vous devez mettre l'adresse IP de votre cluster plutôt que du nœud :
bind-address = 192.168.1.64
Normalement, vous ne devriez PAS pouvoir relancer le serveur MySQL car l'hôte sur lequel le serveur doit tourner n'existe pas encore. Ce sera Pacemaker qui gèrera cela...
Ok, notre serveur MySQL est maintenant opérationnel (quelle ironie !).
Corosync
Pour Corosync, c'est super simple, il y a 4 commandes à taper :
sed -i 's/no/yes/g' /etc/default/corosync
sed -i 's/.*bindnetaddr:.*/bindnetaddr:\ 192.168.1.0/g' /etc/corosync/corosync.conf
sed -i 's/.*mcastaddr:.*/mcastaddr:\ 239.0.0.1/g' /etc/corosync/corosync.conf
sed -i 's/.*mcastport:.*/mcastport:\ 6800/g' /etc/corosync/corosync.conf
C'est tout !
Nous avons donc : autorisé Corosync à démarrer et nous avons configuré l'interface réseau du service.
Avec cette configuration de Corosync, nous venons de finir de configurer tous les logiciels qui peuvent tourner indépendamment du cluster. Maintenant, nous allons passer à l'étape suivante : le clonage de notre nœud afin de créer « node2 ».
Clonage de la VM
Avant de cloner notre machine, il vous faut désactiver le démarrage des précédents services au boot puisqu'ils dépendent du volume DRBD et donc échouent. Et oui, Apache et MySQL essaient de démarrer mais comme leur répertoire de données est sur la partition LVM qui n'est pas montée automatiquement au boot (car dépendant de DRBD qui démarre en fin de séquence de boot), ça merde.
update-rc.d -f mysql remove
update-rc.d -f apache2 remove
update-rc.d -f drbd remove
halt -t now
Mais la véritable raison est que ces services seront lancés par le manager du cluster (Pacemaker) que l'on va configurer par la suite.
Pour cloner la VM, rien de plus simple...
VBoxManage clonevm N1 --mode machine --name N2 --register
VBoxManage startvm N2
A ce niveau-là, la nouvelle VM se lance et vous la trouverez au même statut que la première mais cependant, il faudra faire quelque retouches car c'est peut-être des clones mais ils doivent néanmoins rester identifiables.
A commencer par le hostname, les cartes réseaux puis l'IP statique :
Mettre à jour le hostname
Rien de plus facile, c'est basique :
echo node2 > /etc/hostname
Mettre à jour les interfaces réseau
Quand VirtualBox clone une VM, il assigne automatiquement par défaut des nouvelles adresses MAC au clone (normal) et ajoute les lignes nécessaires dans /etc/udev/rules.d/70.persistent-net.rules ; il faut donc faire un peu de ménage sur le clone mais avant, repérons les adresses MAC es interfaces générées par VirtualBox :
VBoxManage showvminfo N2 | grep MAC
NIC 1: MAC: 080027B66CC0, Attachment: Bridged Interface 'en1: AirPort', Cable connected: on, Trace: off (file: none), Type: 82540EM, Reported speed: 0 Mbps, Boot priority: 0, Promisc Policy: allow-all
NIC 2: MAC: 080027419386, Attachment: Internal Network 'intnet', Cable connected: on, Trace: off (file: none), Type: 82540EM, Reported speed: 0 Mbps, Boot priority: 0, Promisc Policy: deny
Maintenant, regardons les interfaces réseau sur notre VM :
less /dev/udev/rules.d/70.persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100e (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="08:00:27:ec:7e:48", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1"
# PCI device 0x8086:0x100e (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="08:00:27:ff:1c:0f", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
# PCI device 0x8086:0x100e (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="08:00:27:41:93:86", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth2"
# PCI device 0x8086:0x100e (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="08:00:27:b6:6c:c0", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth3"
Les deux premières cartes sont celles de la première VM, on peut donc les supprimer. Pour les autres lignes, soit vous remplacez le numéro de l'interface réseau pour celle qui correspond à bonne adresse MAC, soit vous changez les numéros des interfaces dans /etc/network/interfaces.
Personnellement, je préfère changer le numéro des interfaces dans ce fichier histoire que nos clones soient configurés sur les même interfaces (logique).
Mettre à jour l'adresse IP statique
Là encore, c'est du connu donc pas d'inquiétude :
sed -i 's/10.0.0.1/10.0.0.2/g' /etc/network/interfaces
reboot
Note : à ce niveau-là, je crois que le plus simple est de redémarrer car je ne pense pas que l'OS puisse encaisser le changement à chaud des déclaration d'interfaces réseau dans /etc/udev/.. donc un redémarrage me semble approprié.
La seconde machine (aka « node2 ») est maintenant opérationnelle.
Synchronisation DRBD et test
Lancez maintenant en parallèle la première machine et mettez en lancez les ressources DRBD sur les deux machines :
service drbd start
cat /proc/drdb
Et là, ô surprise, la synchronisation commence :
version: 8.3.7 (api:88/proto:86-91)
srcversion: EE47D8BF18AC166BE219757
1: cs:SyncSource ro:Secondary/Secondary ds:UpToDate/Inconsistent C r----
ns:703528 nr:0 dw:0 dr:704452 al:0 bm:53 lo:0 pe:16 ua:231 ap:0 ep:1 wo:b oos:340944
[============>.......] sync'ed: 67.5% (340944/1044412)K
finish: 0:00:17 speed: 19,940 (18,512) K/sec
Pour vérifier que tout a bien fonctionné, on va monter le volume DRBD sur « node1 », lancer le service Apache et nous allons ensuite faire la même chose sur « node2 » :
# node1
drbdadm primary r0
mount /dev/drbd1 /var/cluster
service apache2 start
# On récupère l'adresse IP du DHCP :
ip addr show eth0 | grep "inet " | head -n 1 | sed 's/\// /' | awk '{print $2}'
192.168.1.6
Et sur la machine hôte, on vérifie qu'on tombe bien sur « node1 »:
curl https://192.168.1.6
node1
Ok, ça marche donc on va maintenant changer de nœud mais avant, il faut arrêter les services sur « node1 » :
# node1
service apache2 stop
umount /dev/drbd1
drbdadm secondary r0
On lance les services sur « node2 » maintenant :
# node2
drbdadm primary r0
mount /dev/drbd1 /var/cluster
service apache2 start
# On récupère l'adresse IP du DHCP :
ip addr show eth0 | grep "inet " | head -n 1 | sed 's/\// /' | awk '{print $2}'
192.168.1.5
Refaites le test sur votre machine hôte en changeant l'IP (bien sûr) et ça devrait le faire.
Nous venons de faire ce que fera Pacemaker manuellement : on change de machine si l'une d'entre elle tombe. En tapant ces commandes, on réalise bien la dépendance support/service de l'architecture.
En parlant de Pacemaker, c'est la prochaine étape.
Pacemaker
Pacemaker est un outil de gestion de cluster. Il peut gérer différents services de tous genre et pour cela, il utilise entre autres les librairies de Heartbeat. Corosync est un service de messagerie (d'où l'adresse multicast) qui va permettre à Pacemaker de communiquer dans le cluster.
Dans la configuration de Corosync, vous avez une partie déclaration de service qui permet de lancer Pacemaker mais en dehors de cela, je ne sais pas du tout où est géré Pacemaker. Dans Fedora, le service était gérable comme n'importe quel autre service système mais apparemment pas sous Debian...
Pour configurer Pacemaker, on utilise la CLI crm et pour voir la configuration actuelle :
crm configure show
node node1
node node2
property $id="cib-bootstrap-options" \
dc-version="1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b" \
cluster-infrastructure="openais" \
expected-quorum-votes="2"
La commande crm est une commande interactive comme lorsqu'on configure un switch. Vous verrez juste après.
Note : la configuration de Pacemaker est basée sur du XML, ce qui la rend interopérable et surtout vérifiable avec des schémas XSD. Par exemple, on peut vérifier une configuration avec la commande crm_verify -L. La configuration de Pacemaker est aussi visible en format XML : crm configure show xml ainsi que le statut des nœuds : crm node status xml ;).
Pour monitorer vos nœuds, utilisez la commande crm_mon :
crm_mon -1
============
Last updated: Wed Jan 18 22:00:31 2012
Stack: openais
Current DC: node2 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
0 Resources configured.
============
Online: [ node1 node2 ]
Note : l'option « -1 » permet de faire un affichage one-shot.
Avant de commencer à ajouter des ressources à notre cluster, nous allons définir 3 petites propriétés préliminaires :
crm configure
crm(live)configure# property no-quorum-policy="ignore" stonith-enabled="false" \
default-resource-stickiness="100"
crm(live)configure# commit
crm(live)configure# show
node node1
node node2
property $id="cib-bootstrap-options" \
dc-version="1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
no-quorum-policy="ignore" \
stonith-enabled="false" \
default-resource-stickiness="100"
Note : la CLI CRM semble fonctionner qu'avec le shell BASH (attribué par défaut) à l'heure où j'écris ces lignes donc si vous avez une erreur du genre "no profile", changez de shell :
chsh -s /bin/bash && exit
Le quorum est une notion (plus politique qu'informatique) un peu floue pour moi : il s'agirait d'un pouvoir de vote basé sur le nombre de nœuds qui doit être actif et sain afin qu'un service puisse être fourni si j'ai bien compris. Dans le cas où nous avons seulement que 2 nœuds, nous n'avons pas besoin de spécifier ce facteur.
Le STONITH (Shoot The Other Node In The Head) est une notion super importante car c'est ce qui permet de détecter et d'isoler un nœud défectueux. N'étant pas expert, j'ai lu que le STONITH utilisait des procédés plus approfondis que le simple ping ou l'accès SSH afin de déterminer si une machine est encore disponible ou pas.
Domaine de connaissance à développer... Inutile ici mais devrait être activé en production.
Au vue de l'architecture basique que nous entreprenons ici, nous n'avons pas besoin de ces deux notions. Si j'ai le temps, cela fera l'objet d'articles futurs.
Enfin, la dernière propriété permet de figer les ressources à un certain degré quand elles ont migré sur un autre nœud : on part du principe que si les ressources ont migré, c'est que le nœud qui les accueillait est tombé et/ou défaillant.
Cette propriété permet de figer les ressources sur le nouveau nœud évitant un nouveau basculement dès lors que l'autre nœud soit opérationnel.
Il s'agit d'une simple mesure de sécurité car si les ressources migrent automatiquement vers le nœud qui vient de tomber, il se peut que ce nœud tombe à nouveau... Et si un nœud tombe, il doit être inspecté donc on évite de le solliciter.
Les ressources Pacemaker
Comme écrit précédemment, Pacemaker est un outil de monitoring de cluster et donc se doit de pouvoir prendre en charge un maximum de service (d'où sa popularité). Ces services qui sont déclarés en temps que ressource dans Pacemaker sont configurable via des scripts (manipulés par Pacemaker).
Au vu du nombre de services proposés par Pacemaker, ils sont répartis par classes de service que vous pouvez découvrir avec la commande crm ra classes. Cette commande vous sortira une classe par ligne et ses catégories sur la même ligne.
Pour voir les scripts (services = ressources) gérés dans ces classes, il faudra taper cette commande : crm ra list ocf (dans le cas où vous souhaitez lister les ressources de la classe « ocf »).
N'hésitez pas à lire un peu la documentation de Pacemaker qui vous sera d'une grande utilité.
Ajouter la ressource d'IP virtuelle
Vous souvenez-vous de l'adresse IP de notre serveur MySQL ? C'est cette adresse-ci que nous allons utiliser, cette adresse sera virtuelle et pointera sur Pacemaker qui à son tour déterminera quel nœud est le plus en état de fournir les services.
Ajoutons cette ressource :
crm configure
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 \
params ip=192.168.1.64 nic=eth0 iflabel=VIP op monitor interval=10s
crm(live)configure# commit
On utilise la commande [primitive](https://www.clusterlabs.org/doc/crm_cli.html#cmdhelp_configure_primitive) pour déclarer une ressource, ensuite son nom, son nom de script précédé de son espace de nom, ses paramètres et enfin sa configuration pour le monitoring.
Note : pour voir tous les paramètres de la primitive IPaddr2 : crm ra info ocf:heartbeat:IPaddr2 | more.
Pour visualiser en live l'évolution de votre configuration, je vous conseille de la faire sur un nœud et de laisser tourner un crm_mon sur l'autre.
Tests
Pour tester le bon fonctionnement de notre adresse IP virtuelle, pinguez 192.168.1.64 depuis votre machine hôte :
# Machine hôte (3s entre chaque ping)
ping -i 3 192.168.1.64
Pendant que ça ping, faites "tomber" le nœud sur lequel la ressource tourne :
# En supposant que vip tourne sur node2
crm node standby node2
# Ca ping toujours car la ressource à dû migrer sur node1
# On down le dernier noeud
crm node standby node1
# Ca ping plus
# On restaure les 2 noeuds
crm node online node2
crm node online node1
Vous venez de toucher du doigt l'intérêt majeur de Pacemaker, permettant ainsi de créer une architecture haute disponibilité !
Attention : à partir de maintenant, on ne commit plus la configuration de Pacemaker jusqu'à qu'elle soit entièrement finie !
Ajouter la ressource Apache
Pour ajouter la ressource Apache, c'est très simple puisque le script lsb:apache2 gère tout :
crm configure
crm(live) configure# primitive apache lsb:apache2
Je sais que ça démange de commiter mais, franchement, c'est tellement plus beau quand tout pète marche bien à la fin...
Ajouter la ressource MySQL
Ajouter la ressource MySQL est au moins aussi simple qu'Apache:
crm(live) configure# primitive mysql lsb:mysql
Ajouter la ressource DRBD et celle du système de fichier
Ici les choses vont se compliquer un peu : comme nous l'avons vu précédemment, il y a un ordre et donc des dépendances à respecter :
- Lancement de DRBD
- Assignation du périphérique DRBD en maître
- Montage du volume LVM
Il va falloir respecter cela avec Pacemaker et gérer les dépendances. Donc de la même manière que pour l'IP virtuelle, on va déclarer deux nouvelles ressources :
- La ressource DRBD
- La ressource système de fichier (pour monter le volume)
La ressource DRBD est une primitive en tant que soit mais doit aussi apporter plus de détails car c'est une ressource maître/esclave, et donc une fois déclarée, il va falloir spécifier tout cela grâce à la commande [ms (ou master)](https://www.clusterlabs.org/doc/crm_cli.html#cmdhelp_configure_ms) :
crm(live)configure# primitive drbd ocf:linbit:drbd \
params drbd_resource="r0" op monitor interval="30s"
ms ms_drbd drbd meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" notify="true"
Ici nous venons de déclarer la ressource DRBD et de la configurer afin qu'il n'y ait toujours qu'un seul maître à la fois. En fait, quand la ressource va changer de nœud, vous verrez que les deux périphériques vont seront esclaves avant de passer en maître sur le nœud de destination.
Maintenant, occupons-nous du système de fichier :
crm(live)configure# primitive fs ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/r0" directory="/var/cluster" fstype="reiserfs"
Aussi simple que cela, on spécifie le périphérique à monter, son point de montage et enfin son type de système de fichier.
Non, on ne commit toujours pas... Vous allez comprendre pourquoi avec la suite.
Contraintes et ordre des ressources
C'est sans aucun doute la partie la plus complexe du projet car elle demande une certaine logique et surtout une bonne connaissance des dépendances entre les différentes couches de notre architecture.
Pour commencer, nous allons analyser quelle ressource doit impérativement travailler avec une autre. Vous allez me dire toute mais figurez-vous que non.
Certes Apache ou MySQL ne peut pas se lancer sans ses données mais ses données ne sont pas propres au système de fichier !
On pourrait très bien avoir des données MySQL totalement différentes sur un serveur que sur un autre et idem pour Apache. Ces services n'ont pas besoin de LEURS données en soi mais d'un système de fichier sur lequel on pourra y trouver des données qu'ils pourront lire.
Dans un scénario un peu sadique, on pourrait placer une application Web sur un nœud et une autre sur un autre nœud et avoir accès à telle ou telle application en fonction de localisation des ressources... Inutile hein.
Ce qui est primordial est de regrouper l'IP virtuelle, MySQL et Apache dans un premier temps :
crm(live)configure# group webapp vip mysql apache
Ici, nous avons créé un groupe « webapp » qui contient l'IP virtuelle, MySQL et Apache.
Attention : l'ordre de déclaration est important : si la ressource « vip » ne démarre pas pour une raison ou une autre, alors MySQL et Apache ne démarreront pas non plus. De la même manière, si une ressource échoue, alors c'est le groupe entier qui sera en échec.
C'est une des particularités des groupes.
Maintenant, on manipule un groupe de ressources pour la suite de nos dépendances.
A partir d'ici, « webapp » doit forcément avoir besoin du système de fichier pour être lancé ; donc cela implique que « webapp » et « fs » doivent être sur le même nœud pour que cela puisse se faire.
Pacemaker offre la commande [colocation](https://www.clusterlabs.org/doc/crm_cli.html#cmdhelp_configure_colocation) qui permet justement de forcer deux (ou plus) ressources à cohabiter sur le même nœud :
crm(live)configure# colocation webapp-w-fs inf: webapp fs
Cette déclaration « webapp-w-fs » (l'application Web avec le système de fichier) impose au cluster de faire cohabiter ces deux ressources.
Note : l'ordre des paramètres n'est pas important mais on peut tout de même spécifier des priorités en mettant des ressources entre parenthèses.
Note 2 : le paramètre « inf: » (« infinity ») est le nombre de fois que Pacemaker essaiera de réaliser cette contrainte.
Ok, nous avons la contrainte suivante établie : « webapp » doit être sur le même nœud que « fs ». Seulement, « fs » à besoin de « drbd » en maître pour pouvoir être monté :
crm(live)configure# colocation fs-w-drbd inf: fs ms_drbd:Master
Et voila ! On spécifie que « fs » a besoin de la ressource « drbd » en état maître.
Si on résume bien, on a fait tout le tour des contraintes de localisation des ressources mais maintenant se pose un autre souci : comment être certain que les ressources se lancent bien dans le bon ordre ?
Pour cela, Pacemaker a la commande [order](https://www.clusterlabs.org/doc/crm_cli.html#cmdhelp_configure_order) qui permet de définir un ordre dans les ressources. Par exemple, on ne peut pas lancer le groupe « webapp » avant que le système de fichier soit monté :
crm(live)configure# order webapp-aft-fs inf: fs webapp
Avec cette commande, « webapp » sera lancé après le système de fichier !
Mais pareil, le système de fichier ne peut pas être monté si la ressource « drbd » n'est pas encore en place et là comme c'est une ressource maître/esclave, il y a une particularité :
crm(live)configure# order fs-aft-drbd inf: ms_drbd:promote fs:start
On remarque ici que la commande « order » peut s'affiner en tenant compte des actions associées aux ressources : on démarre la ressource « fs » une fois que la ressource « ms_drbd » est promu maître.
La configuration de Pacemaker est maintenant presque finie... En tapant un « show », vous devriez avoir ça sous les yeux :
crm(live)configure# show
node node1
node node2
primitive apache lsb:apache2
primitive drbd ocf:linbit:drbd \
params drbd_resource="r0" \
op monitor interval="30s"
primitive fs ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/r0" directory="/var/cluster" fstype="reiserfs"
primitive mysql lsb:mysql
primitive vip ocf:heartbeat:IPaddr2 \
params ip="192.168.1.64"
group webapp vip apache mysql
ms ms_drbd drbd \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
colocation fs-w-drbd inf: fs ms_drbd:Master
colocation webapp-w-fs inf: webapp fs
order fs-aft-drbd inf: ms_drbd:promote fs:start
order webapp-aft-fs inf: fs webapp
property $id="cib-bootstrap-options" \
dc-version="1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore" \
default-resource-stickiness="100"
Si c'est ok, il vous suffit de commiter de voir apparaître les ressources sur le crm_mon de l'autre nœud :
crm(live)configure# commit
Et sur l'autre nœud :
crm_mon
============
Last updated: Mon Jan 23 01:34:15 2012
Stack: openais
Current DC: node1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
3 Resources configured.
============
Online: [ node2 node1 ]
fs (ocf::heartbeat:Filesystem): Started node1
Resource Group: webapp
vip (ocf::heartbeat:IPaddr2): Started node1
mysql (lsb:mysql): Started node1
apache (lsb:apache2): Started node1
Master/Slave Set: ms_drbd
Masters: [ node1 ]
Slaves: [ node2 ]
Votre cluster est maintenant configuré !
Avant de passer aux tests, on va sauvegarder la conf' quand même.
Dumper et injecter une configuration
Pour dumper la configuration, on utilise la commande [save](https://www.clusterlabs.org/doc/crm_cli.html#cmdhelp_configure_save) :
crm configure save /root/pcmk.conf
crm configure save xml /root/pcmk.conf.xml # Version XML
Et pour la charger (et accessoirement remplacer la configuration actuelle) :
crm configure load replace /root/pcmk.conf
Tests
Pour tester : tout est permis. On commence léger avec le gestionnaire de nœud de Pacemaker et ensuite, c'est selon votre imagination.
Comme vu tout à l'heure pour tester l'IP virtuelle, voici comment mettre en pause un nœud :
crm node standby node1
Puis pour le remettre en ligne :
crm node online node1
Maintenant, faites des scénarios de test : arrêtez un nœud, puis l'autre, puis relancez-les un par un mais pas forcément dans l'ordre d'arrêt (utile pour tester la bonne configuration de DRBD ou sa politique de split-brain).
Sinon, depuis votre hôte :
VBoxManage controlvm N1 poweroff
VBoxManage modifyvm N1 --cableconnected2 off
VBoxManage startvm N1
Note : il se peut que la ressource DRBD ne se rétablisse pas bien selon les scénarios... Je ne sais pas si c'est une faute de configuration ou un bug mais si vous avez une piste, je suis preneur.
Vous pouvez toujours faire des opérations barbares comme un umount /var/cluster et tester ce que cela donne... Dans la grande théorie, tant qu'une machine est allumée, elle devrait pouvoir vous servir Apache et MySQL.
N'oubliez pas de faire des tests d'insertion en base données et de vérifier si les derniers ajouts sont bien présents suite au coup de foudre.
Ici s'achève ce trèèèèèèès long article sur la mise en place d'une architecture LAMP sur cluster actif/passif. Publié que maintenant, je bosse dessus depuis Novembre dernier... Comme quoi, un "petit" projet peut prendre beaucoup de temps et nécessite beaucoup de documentation (ceux qui me suivent sur mon compte perso Twitter m'ont pas mal entendu gueulé après DRBD).
Si cet article vous a plu ou servi, n'hésitez pas à le partager ou partager vos impressions ! Merci.
Quelques liens utiles :
- Clusters from Scratch
- Cluster sur Binbash.fr
- Linux Cluster - Debian Squeeze, Pacemaker, DRBD, LVM, Apache
- Cluster Xen sous Debian GNU/Linux avec DRBD, Corosync et Pacemaker
- Using Pacemaker with Lustre